
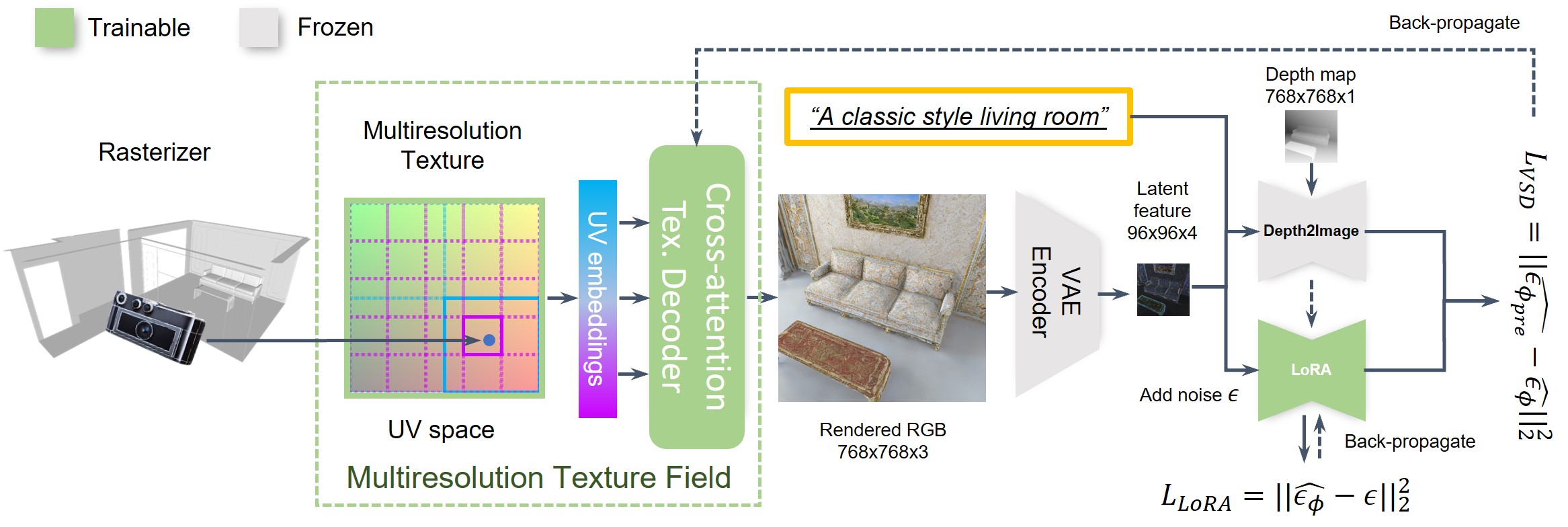
In SceneTex, the target mesh is first projected to a given viewpoint via a rasterizer. Then, we render an RGB image with the proposed multiresolution texture field module. Specifically, each rasterized UV coordinate is taken as input to sample the UV embeddings from a multiresoultion texture. Afterward, the UV embeddings are mapped to an RGB image of shape 768 x 768 x 3 via a cross-attention texture decoder. We use a pre-trained VAE encoder to compress the input RGB image to a 96 x 96 x 4 latent feature. Finally, the Variational Score Distillation loss is computed from the latent feature to update the texture field.
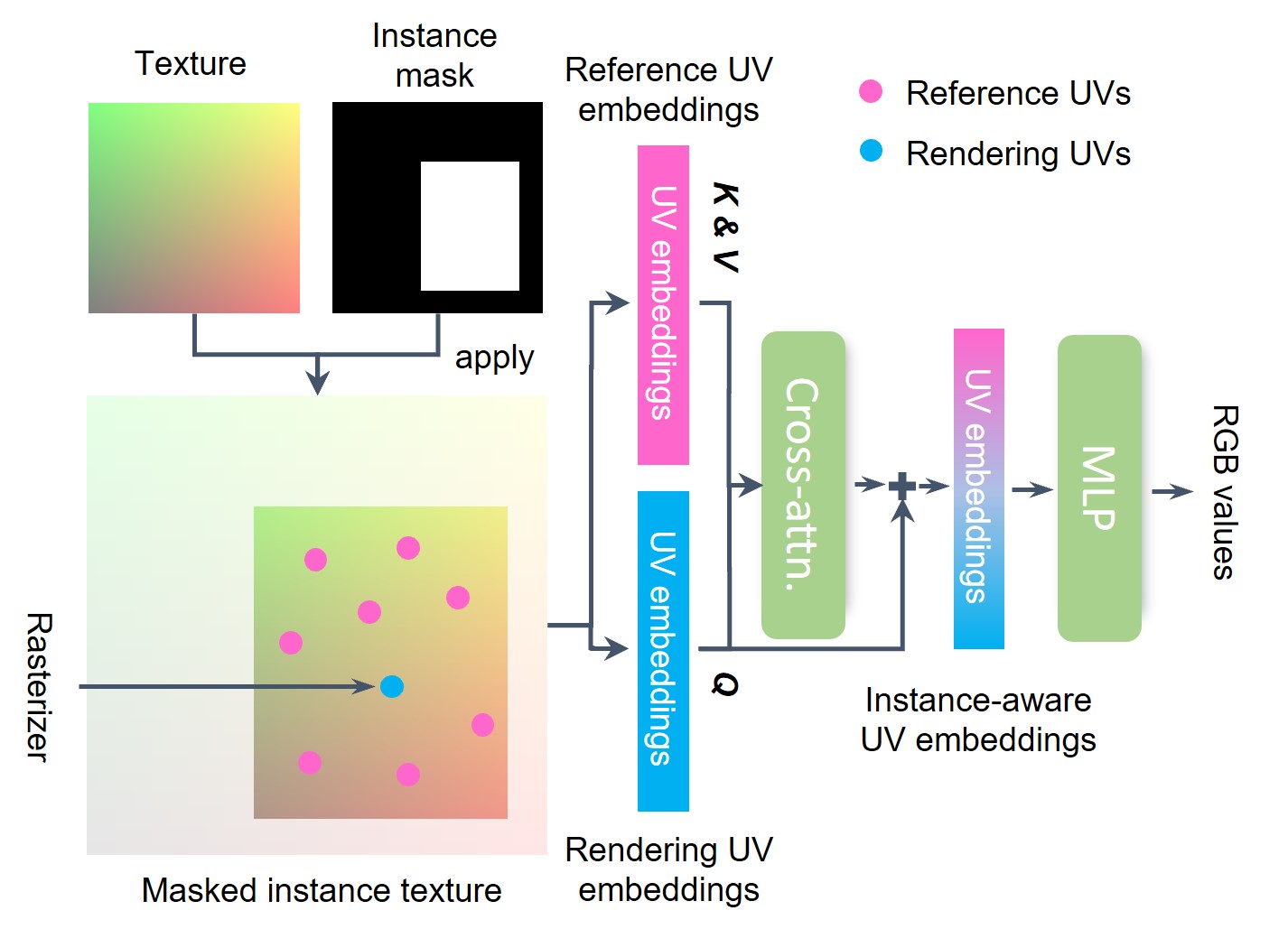
To secure the style-consistency, SceneTex incorporates a Cross-attention Texture Decoder. For each rasterized UV coordinate, we apply a UV instance mask to mask out the corresponding instance texture features. Then, we obtain the rendering UV embeddings for the rasterized locations in the view. At the same time, we extract the texture features for the pre-sampled UVs scattered across this instance as the reference UV embeddings. We deploy a multi-head cross-attention module to produce the instance-aware UV embeddings. Here, we treat the rendering UV embeddings as the Query, and the reference UV embeddings as the Key and Value. Finally, a shared MLP maps the instance-aware UV embeddings to RGB values in the rendered view.
@misc{chen2023scenetex,
title={SceneTex: High-Quality Texture Synthesis for Indoor Scenes via Diffusion Priors},
author={Dave Zhenyu Chen and Haoxuan Li and Hsin-Ying Lee and Sergey Tulyakov and Matthias Nießner},
year={2023},
eprint={2311.17261},
archivePrefix={arXiv},
primaryClass={cs.CV}
}