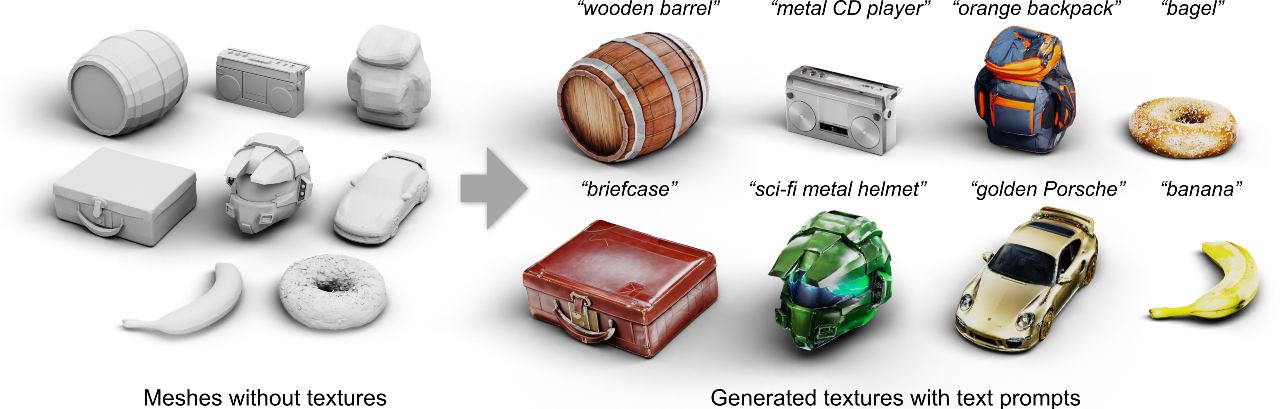
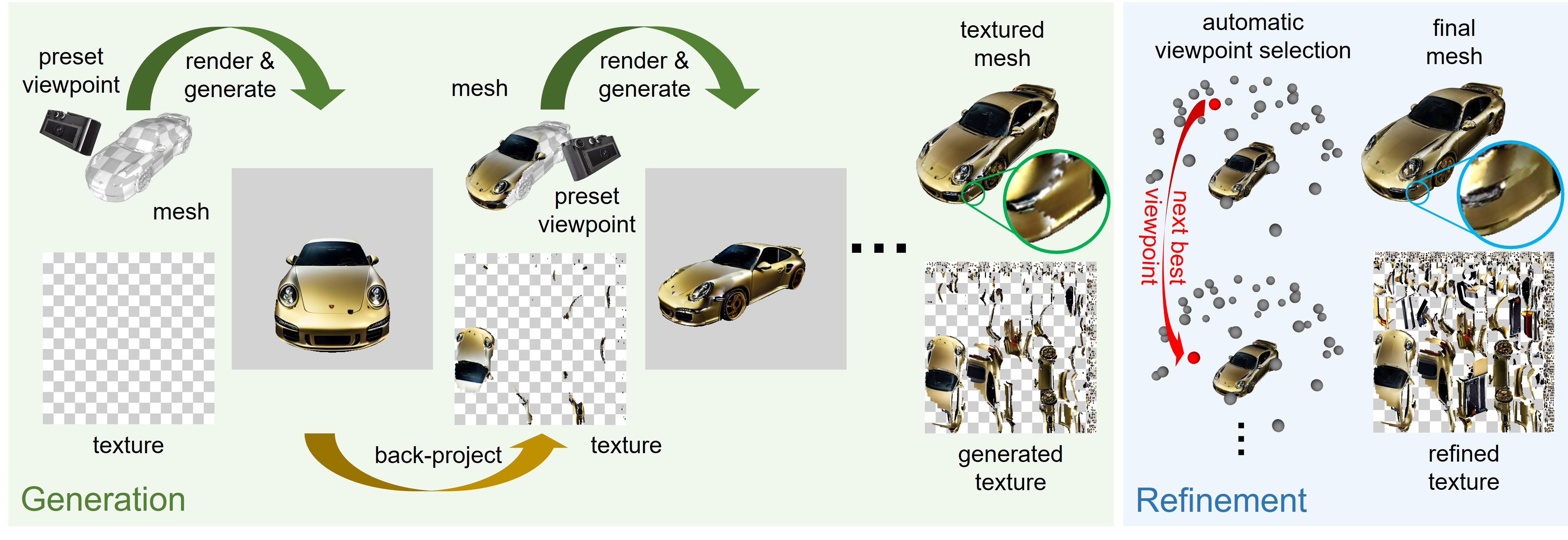
In Text2Tex, we progressively generate the texture via a generate-then-refine scheme
In progressive texture generation, we start by rendering the object from an initial preset viewpoint. We generate a new appearance according to the input prompt via a depth-to-image diffusion model, and project the generated image back to the partial texture. Then, we repeat this process until the last preset viewpoint to output the initial textured mesh.
In the subsequent texture refinement, we update the initial texture from a sequence of automatically selected viewpoints to refine the stretched and blurry artifacts.
@article{chen2023text2tex,
title={Text2Tex: Text-driven Texture Synthesis via Diffusion Models},
author={Chen, Dave Zhenyu and Siddiqui, Yawar and Lee, Hsin-Ying and Tulyakov, Sergey and Nie{\ss}ner, Matthias},
journal={arXiv preprint arXiv:2303.11396},
year={2023},
}