Scan2Cap: Context-aware Dense Captioning in RGB-D Scans
Dave Zhenyu Chen1 Ali Gholami2 Matthias Nießner1 Angel X. Chang2
1Technical University of Munich 2Simon Fraser University

Introduction
We introduce the task of dense captioning in 3D scans from commodity RGB-D sensors. As input, we assume a point cloud of a 3D scene; the expected output is the bounding boxes along with the descriptions for the underlying objects. To address the 3D object detection and description problems, we propose Scan2Cap, an end-to-end trained method, to detect objects in the input scene and describe them in natural language. We use an attention mechanism that generates descriptive tokens while referring to the related components in the local context. To reflect object relations (i.e. relative spatial relations) in the generated captions, we use a message passing graph module to facilitate learning object relation features. Our method can effectively localize and describe 3D objects in scenes from the ScanRefer dataset, outperforming 2D baseline methods by a significant margin (27.61% CiDEr@0.5IoUimprovement).
Video
Results
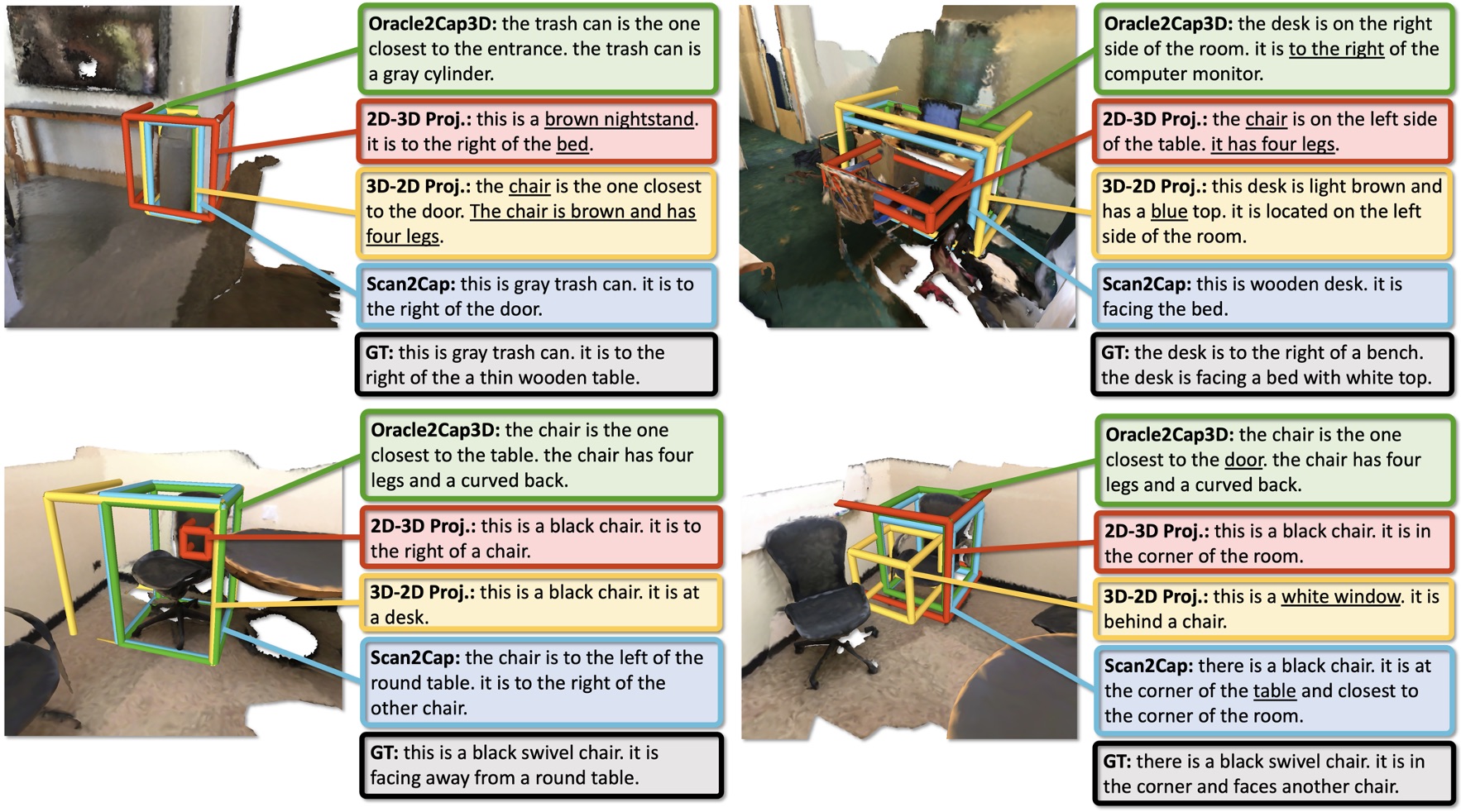
Publication
Paper | arXiv | Code
If you find our project useful, please consider citing us:
@misc{chen2020scan2cap,
title={Scan2Cap: Context-aware Dense Captioning in RGB-D Scans},
author={Dave Zhenyu Chen and Ali Gholami and Matthias Nießner and Angel X. Chang},
year={2020},
eprint={2012.02206},
archivePrefix={arXiv},
primaryClass={cs.CV}
}